

June 18, 2026
The Captions blog
Resources for creators and businesses that want to make great videos. See video editing tips, AI workflows, and the latest product news from Captions. Get Captions

All articles

How to add captions to Instagram Stories

Your AI video skills can now show up on LinkedIn

How to use B-roll: A practical guide to better videos
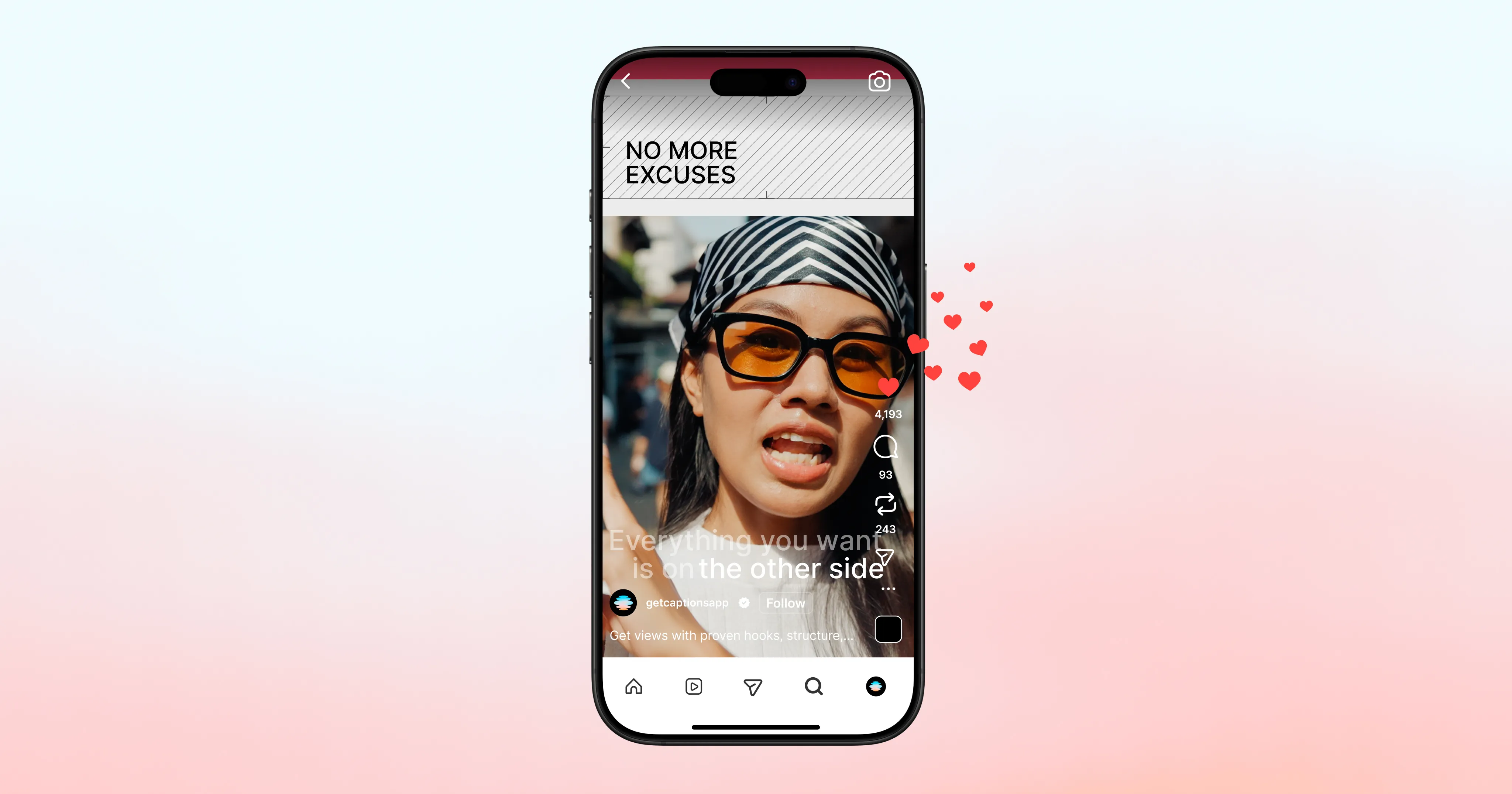
How to make Instagram Reels that actually get views (2026 guide)

Video hooks: How to write a scroll-stopping opening

Repurposing content for social media: Make your videos work harder

Find your video style with AI Edit

20 Instagram hacks to try in 2026

How to add auto-captions to videos (tips and tools)

How to improve your video SEO strategy

Captions and subtitle fonts: 5 ideal styles

How to write a winning AI video prompt

How one real estate agent used Captions to turn videos into sales

How to make a talking head video that actually looks professional
How to get more likes on TikTok: top tips

How to get transcripts of a YouTube video: a quick guide

The best way to turn real estate listing photos into video tours

How to edit TikTok videos for maximum engagement

Earning on Instagram: the follower count question, answered

TikTok Gifts: What they're worth and how to earn more
100+ YouTube channel name ideas to help you stand out

Three new AI Edit video styles, built for any business need

Stop missing out on the benefits of moving text in videos

Meet Cappy: The first AI video editor you can text

The quickest way to make great videos

What’s a digital creator, and how do you become one?

How small teams are moving faster with Captions

How to get the perfect take, no matter where you're looking

Six common types of cuts in film

How to reduce mic background noise before and after recording videos

How to make the trending negative text effect for videos
Announcing Mirage’s $75M growth financing with General Catalyst

Instagram bio ideas to turn viewers into followers (2026)

Mirage achieves SOC 2 compliance

Add music to a video with Captions

Video localization: Best practices for global brands

10 video tips for beginners (that actually stick)

How to make an avatar from photos

Glossary: AI terms every content creator should know

Captions vs. subtitles: How to choose the best option

Why AI avatars are the future of scalable content

Captions brings one-tap video editing to horizontal formats

Easy tools for content clipping
9 TikTok ideas for businesses you can use today

How AI is changing video production

Shaping voices: Crafting expressive audio

Tips for great UGC

How HubSpot built better campaigns with Mirage

Your guide to AI credits

Take a seat in the director's chair.

Editing videos is now as easy as typing.

Introducing Mirage: The future of video starts now.

How a startup improved their creative with Captions

We build synthetic humans. Here's what's keeping us up at night.

AI Video Is Inevitable. How It's Built Is Not.

Seeing voices: Foundation model research report

Mirage: The World's first foundation model for UGC video

Captions announces Series C to invest $100M in AI video research in New York.

Captions announces a $25 million Series B for our AI-powered creative studio